2.3 Dify接入外部知识库¶
学习目标¶
- 了解RAGFlow的定位和优势
- 掌握RAGFlow的安装方法
- 掌握RAGFlow知识库创建
- 掌握dify接入RAGFlow的方法
一、RAGFlow简介¶
1 Dify知识库的不足¶
Dify中的RAG一直被诟病,它的知识库设置不够丰富和灵活,对于不同形式的文档上传,尤其是pdf扫描版,上传识别效果不好,知识库根本回答不了PDF内的内容。为了解决这这些Dify提供了外部知识库API,这样就可以连接到 Dify 之外的知识库并从中检索知识。
接下来给大家重点介绍Dify连接RAGFlow外部知识库的内容
2 什么是RAGFlow¶
RAGFlow是一款基于深度文档理解(deepdoc)构建的开源 RAG引擎。 深度文档理解是RAGFlow对文档解析的一个解决方案,它包含两个组成部分:视觉处理和解析器。其中视觉处理是通过OCR,布局识别,表结构识别来完成图像,PDF,表格的识别的。针对PDF、DOCX、EXCEL和PPT四种文档格式,都有相应的解析器。
能够从各类复杂格式的非结构化数据中提取信息,文本切片过程可视化,还支持手动调整。支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
还集成了各种嵌入模型,rerank模型,提供易用的 API,可以轻松集成到各类企业系统。
官网地址:
安装包镜像完整下载下来,体积非常大,环境要求如下:
- CPU >= 4 核
- 运行内存= 16 GB
- 硬盘 >= 50 GB
- Docker >= 24.0.0 & Docker Compose>= v2.26.1
二、RAGFlow的安装方法¶
1 到github下载项目源码¶
地址如下:
可以克隆也可以直接下载
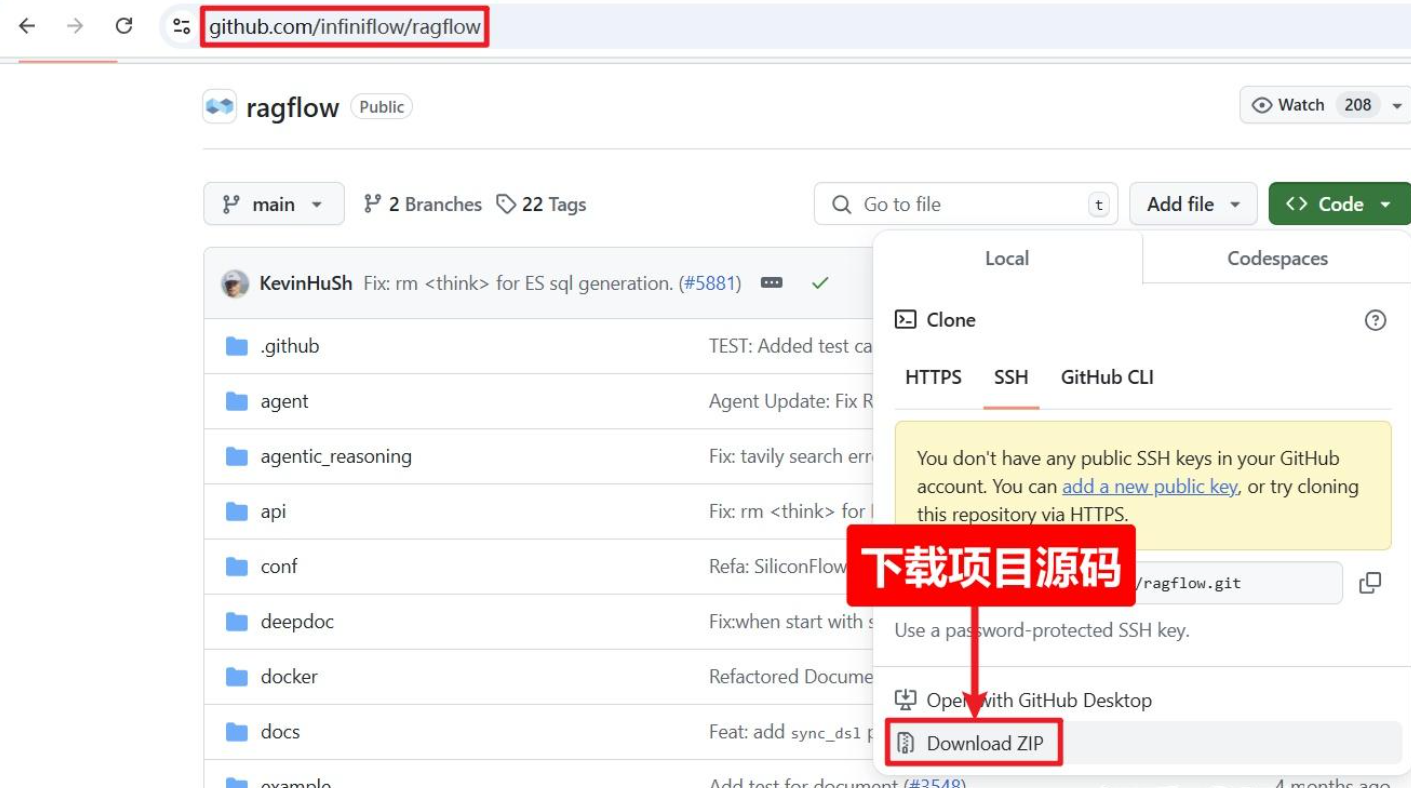
克隆命令如下:
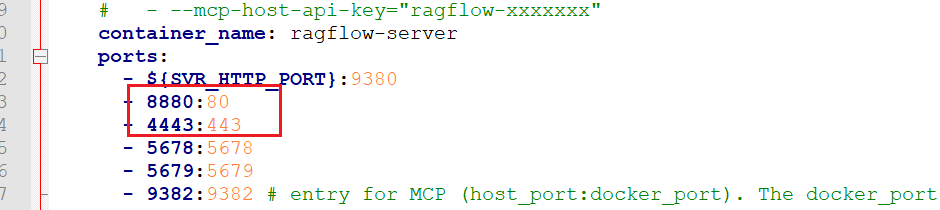
由于前面我们已经安装了Dify项目,这两个项目都依赖了redis,且web端的端口都是默认80端口,因此,为了避免冲突,我们需要修改配置文件。
2 修改web访问默认端口¶
修改文件位置:docker目录下的docker-compose文件
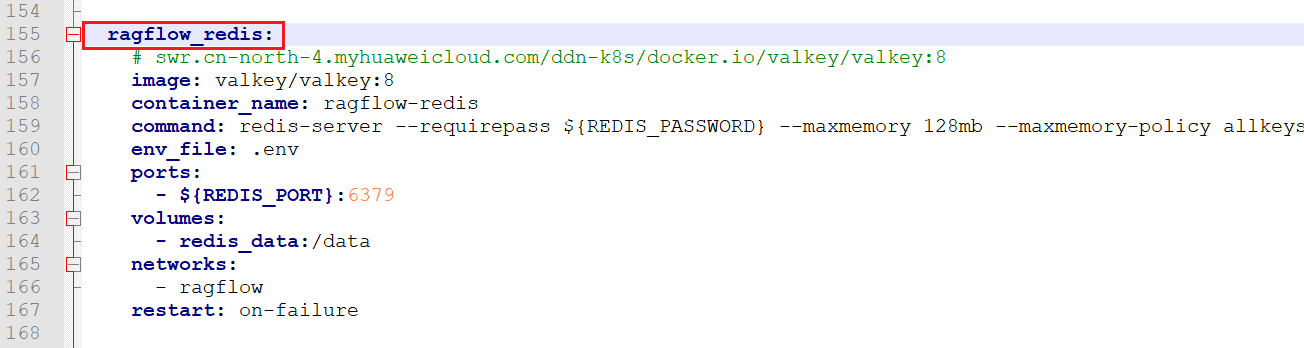
3 修改redis配置¶
修改.env文件

修改docker-compose-base.yml文件
4 启动服务¶
进入docker目录,右键打开命令行:
输入命令:
时间比较久,需要大家耐心等待。
5 打开浏览器访问¶
由于前面,我们把web端口设置为了8880端口,docker镜像拉取后,等待容器启动完成,在浏览器输入:127.0.0.1:8880 即可访问
至此,RAGFlow就安装完成了,注册完成后主页面如下:
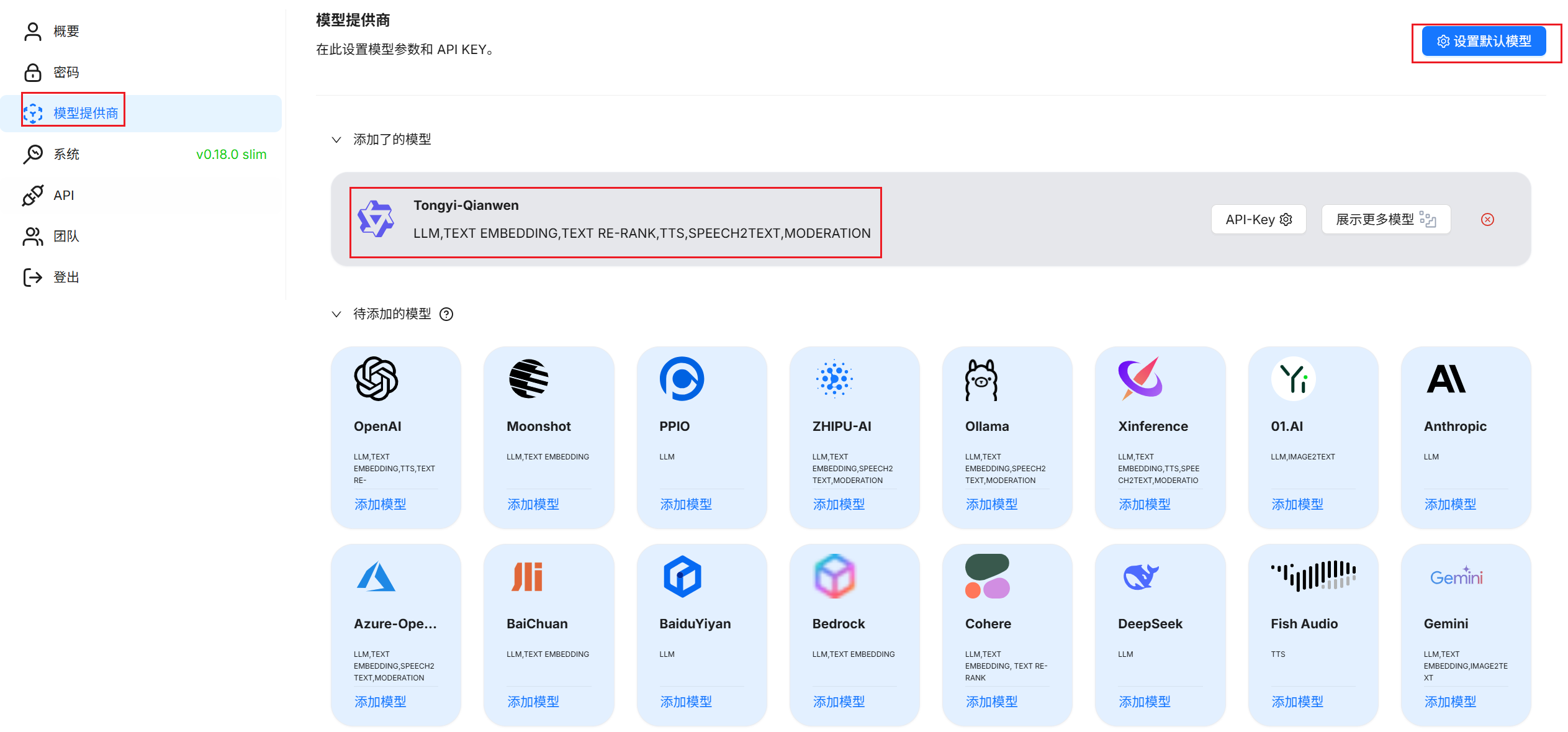
6 模型配置¶
三、RAGFlow 创建知识库¶
1 知识库创建¶
创建好知识库,点击RAGFlow 创建知识库。
2 上传文件¶
我们点击新增加文件。上传我们要解析的私有化知识库文档,然后点击解析完成文档向量化。

可以单个文件解析,也可以批量解析,大家可以根据自己的需要选择使用,解析完成后可进行
3 分片方式¶
进入模型设置界面 选择好嵌入模型和解析方法
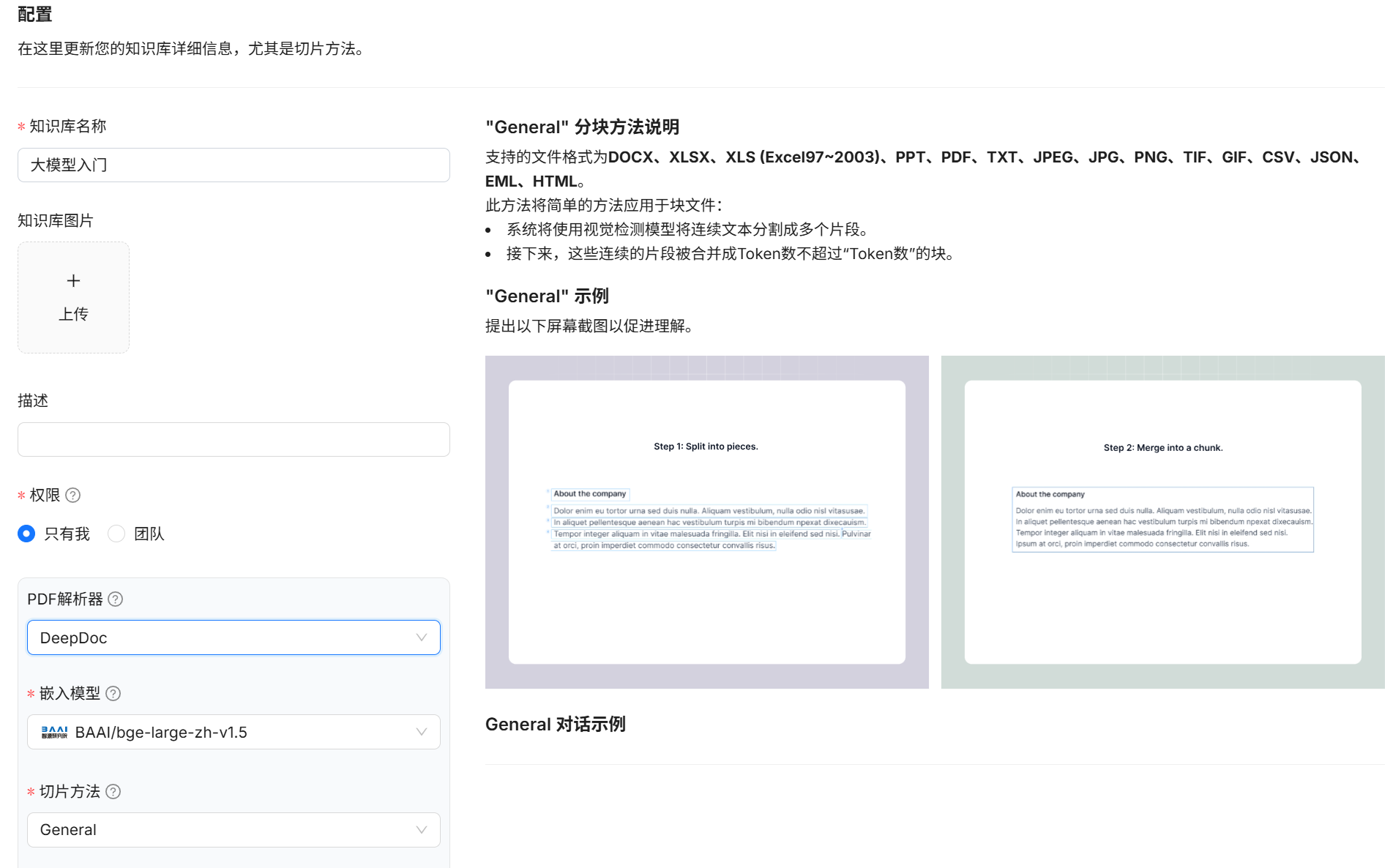
- General 支持的文件格式为DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML、HTML。 此方法将简单的方法应用于块文件:系统将使用视觉检测模型将连续文本分割成多个片段。
- Q&A 支持 excel 和 csv/txt 文件格式。 如果文件是 excel 格式,则应由两个列组成 没有标题:一个提出问题,另一个用于答案, 答案列之前的问题列。多张纸是只要列正确结构,就可以接受。 如果文件是 csv/txt 格式 以 UTF-8 编码且用 TAB 作分开问题和答案的定界符。
- Resume 支持的文件格式为DOCX、PDF、TXT。 简历有多种格式,就像一个人的个性一样,但我们经常必须将它们组织成结构化数据,以便于搜索。 我们不是将简历分块,而是将简历解析为结构化数据。 作为HR,你可以扔掉所有的简历, 您只需与'RAGFlow'交谈即可列出所有符合资格的候选人。
- Manual 仅支持PDF。 我们假设手册具有分层部分结构。 我们使用最低的部分标题作为对文档进行切片的枢轴。 因此,同一部分中的图和表不会被分割,并且块大小可能会很大。
- Table 支持EXCEL和CSV/TXT格式文件。
- Paper 仅支持PDF文件。 如果我们的模型运行良好,论文将按其部分进行切片,例如摘要、1.1、1.2等。 这样做的好处是LLM可以更好的概括论文中相关章节的内容, 产生更全面的答案,帮助读者更好地理解论文。 缺点是它增加了 LLM 对话的背景并增加了计算成本, 所以在对话过程中,你可以考虑减少‘topN’的设置。
- Book 支持的文件格式为DOCX、PDF、TXT。 由于一本书很长,并不是所有部分都有用,如果是 PDF, 请为每本书设置页面范围,以消除负面影响并节省分析计算时间。
- Laws 支持的文件格式为DOCX、PDF、TXT。 法律文件有非常严格的书写格式。 我们使用文本特征来检测分割点。 chunk的粒度与'ARTICLE'一致,所有上层文本都会包含在chunk中。
四、RAGFlow 知识库检索¶
聊天窗口界面

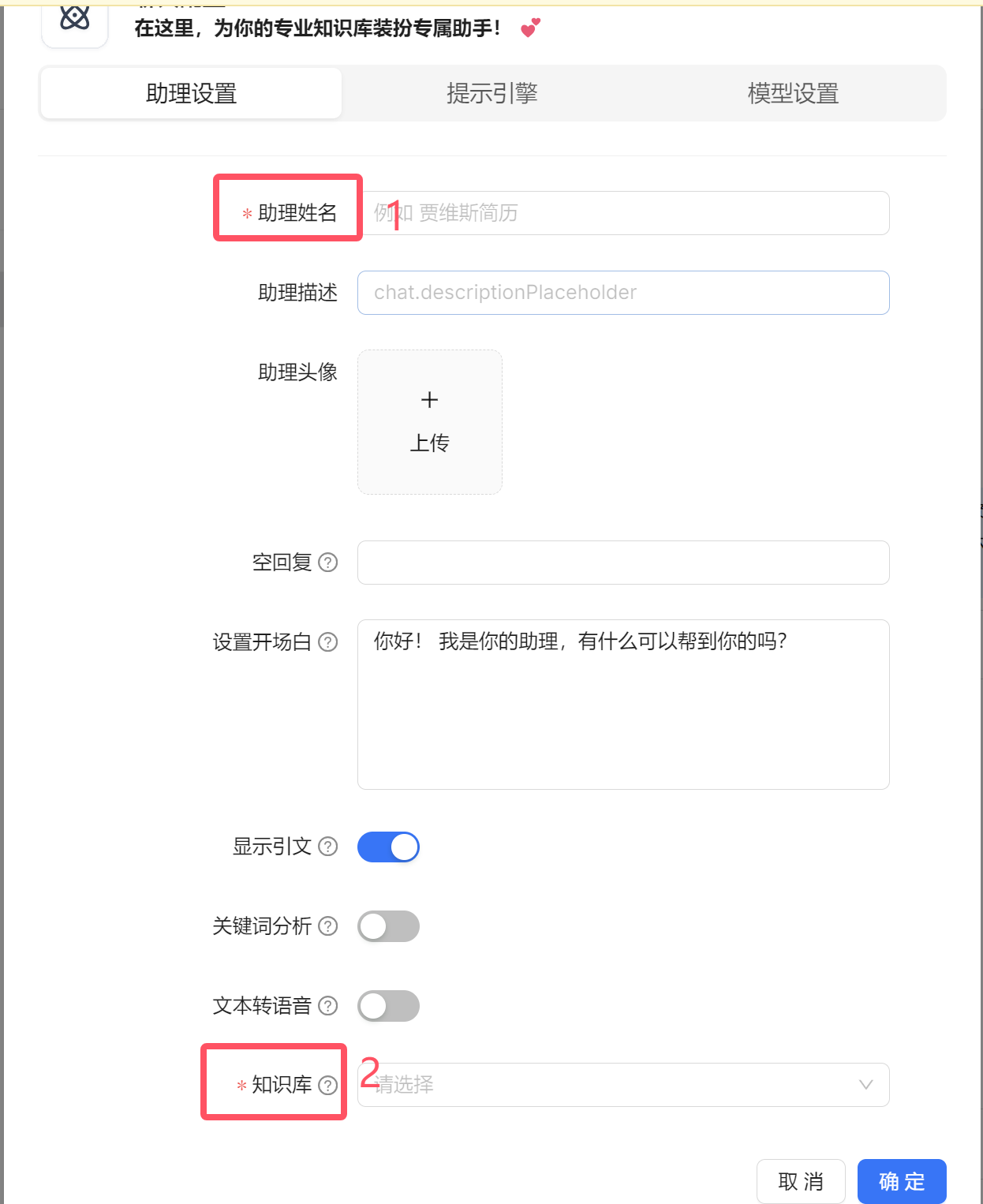
聊天窗口配置有3个选项面板(助理设置、提示引擎、模型设置)
助理设置,这里最关键就是 填写助理姓名和选择指定的知识库
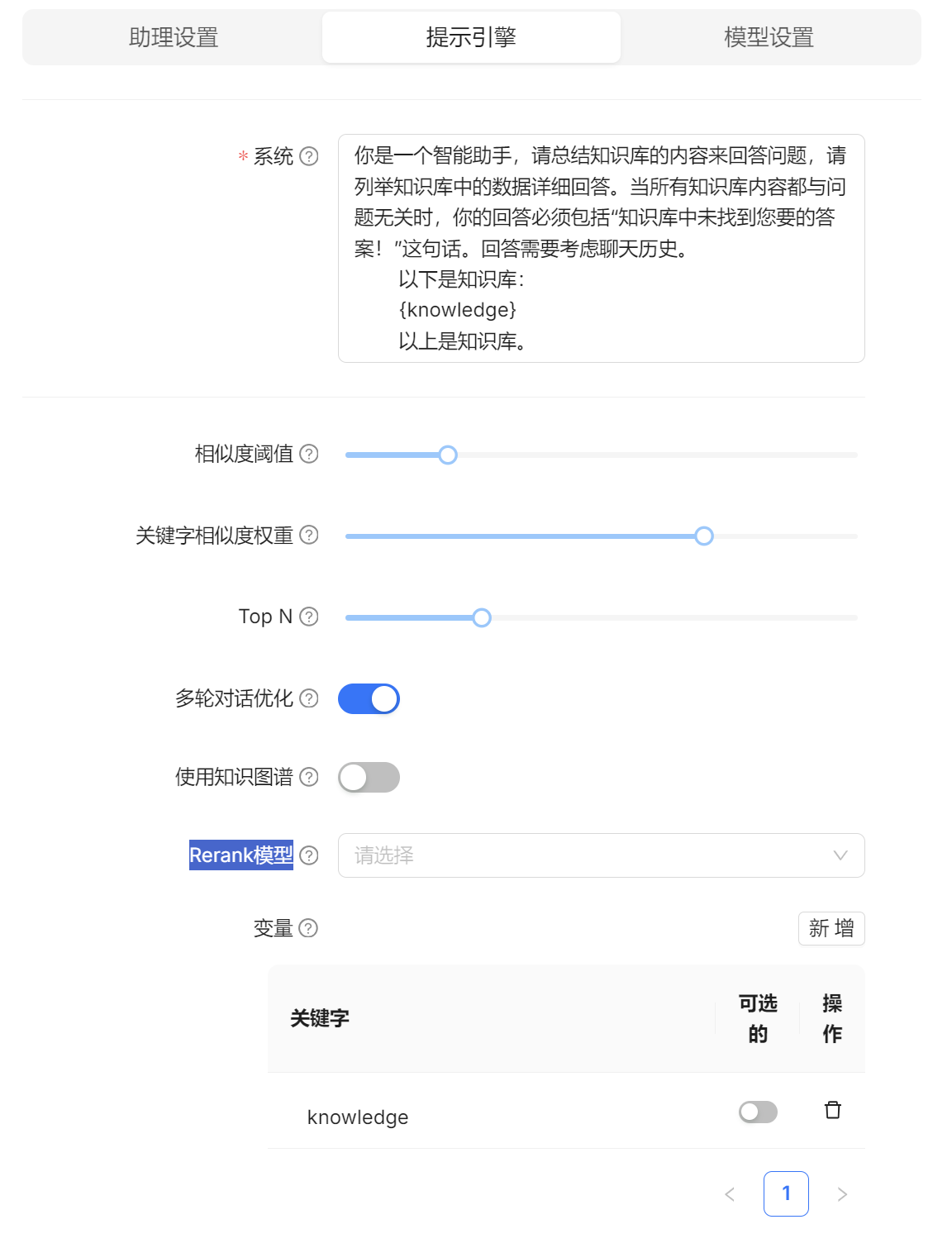
提示引擎 如果大家没有 Rerank模型 可以默认不选。
模型设置,这里需要填写选择一个LLM大语言模型作为推理模型使用。
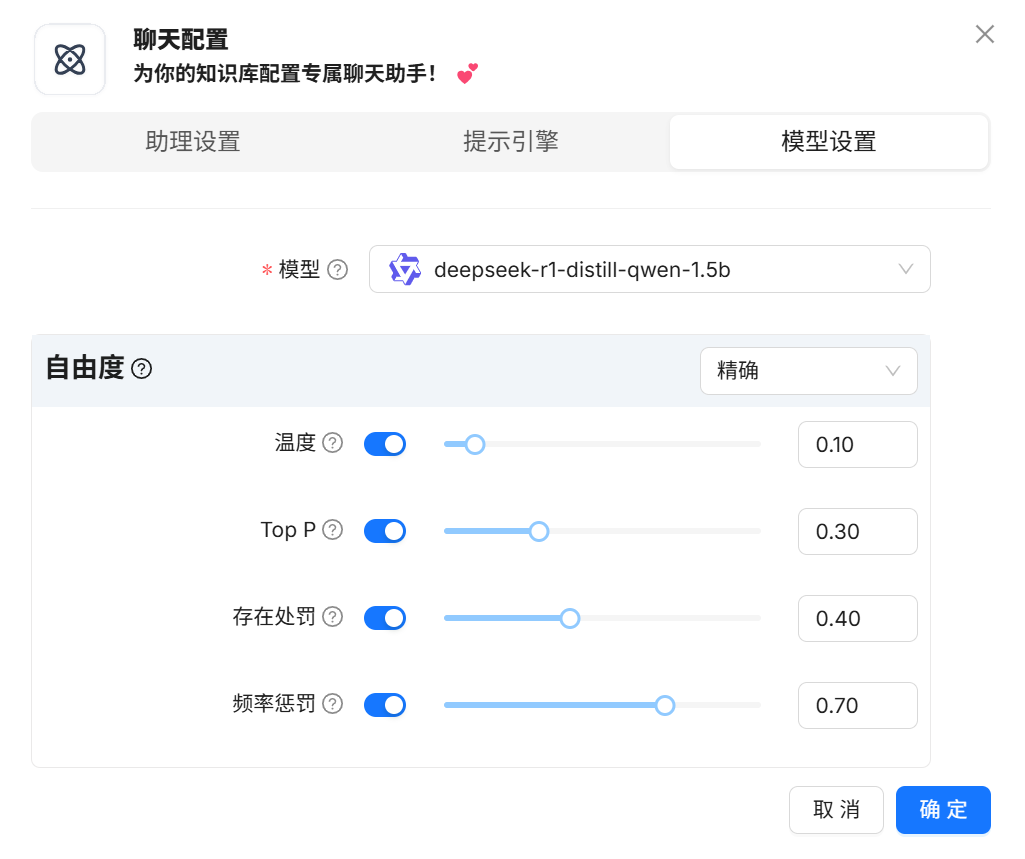
以上设置完成后就可以进行聊天对话了。
以上设置我们完成了RAGFlow相关设置。
五、RAGFlow API 设置¶
接下来我们在dify调用这个RAGFlow ,需要设置一下RAGFlow api key.
1 获取API¶
点击系统右上角,选择 API
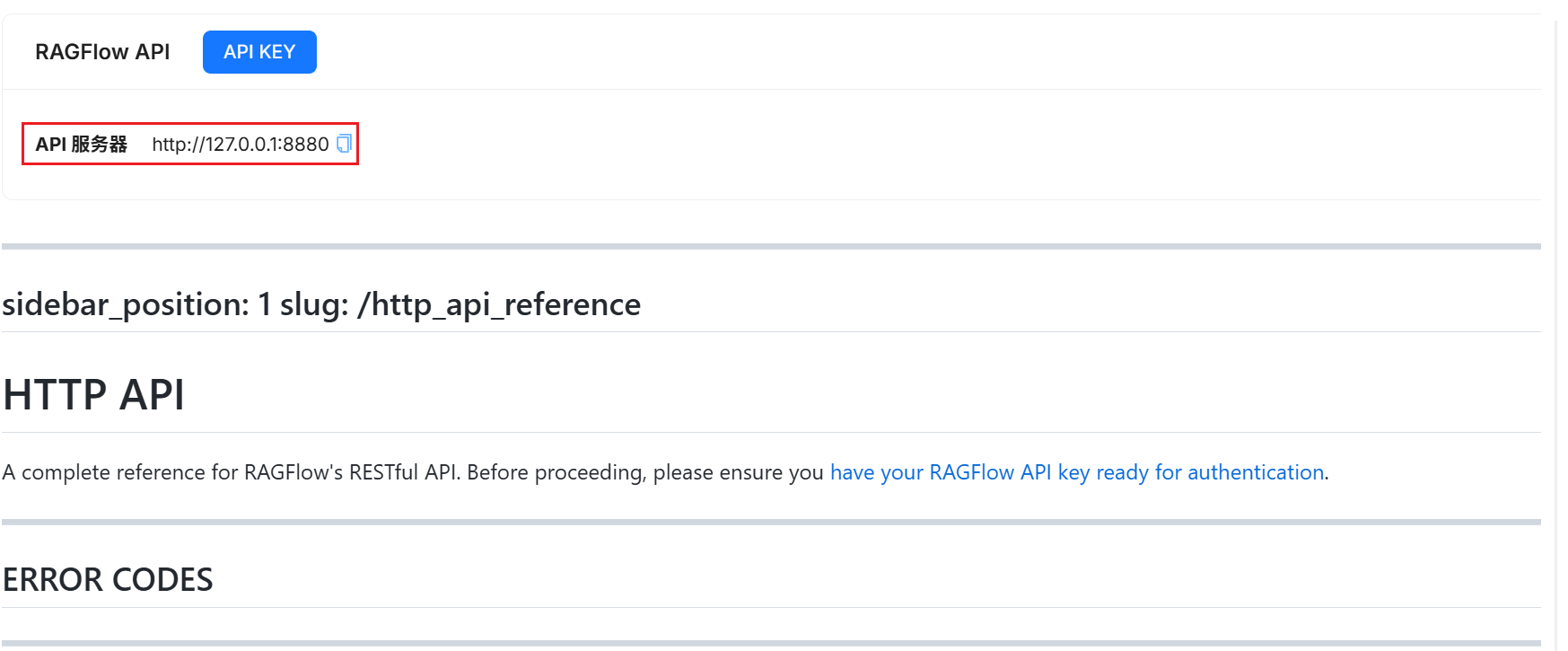
2 获取IP¶
API 服务器 显示RAGFlow 对外提供的IP, 我的显示是http://127.0.0.1:8880!
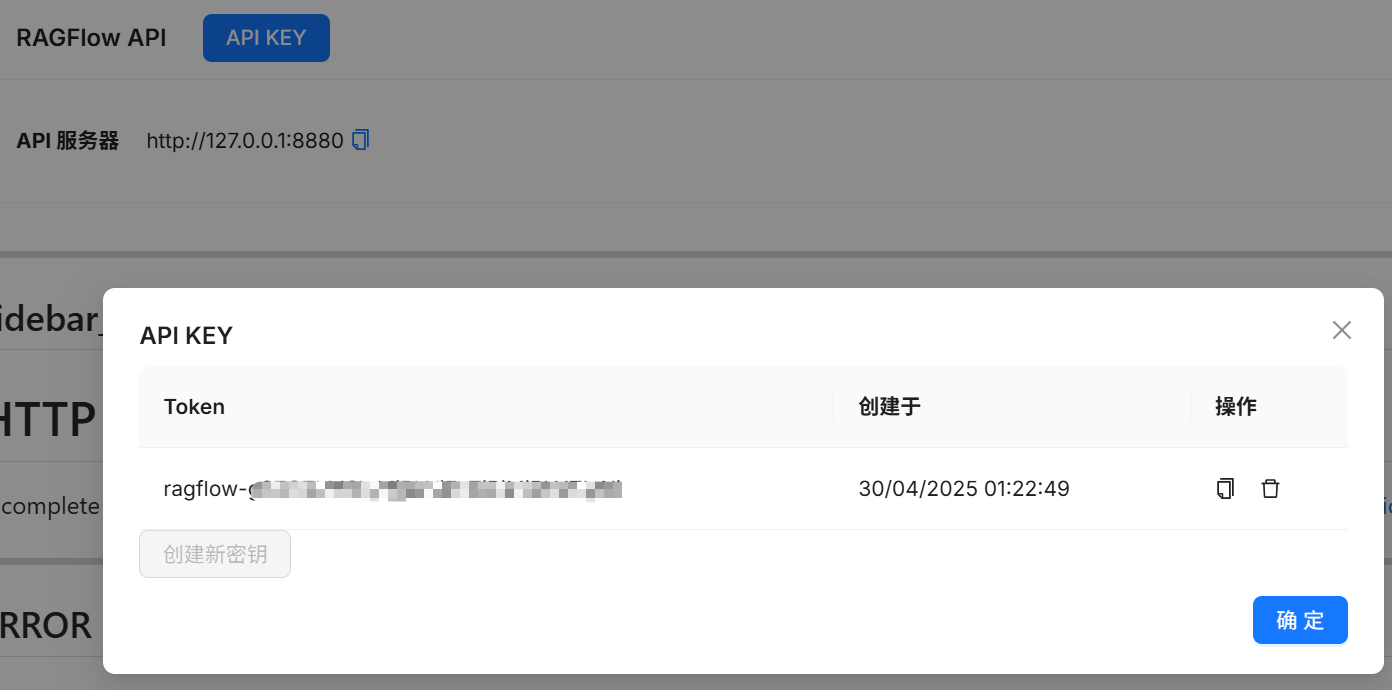
3 获取API key¶
点击上面key生成RAGFlow 对外提供的API
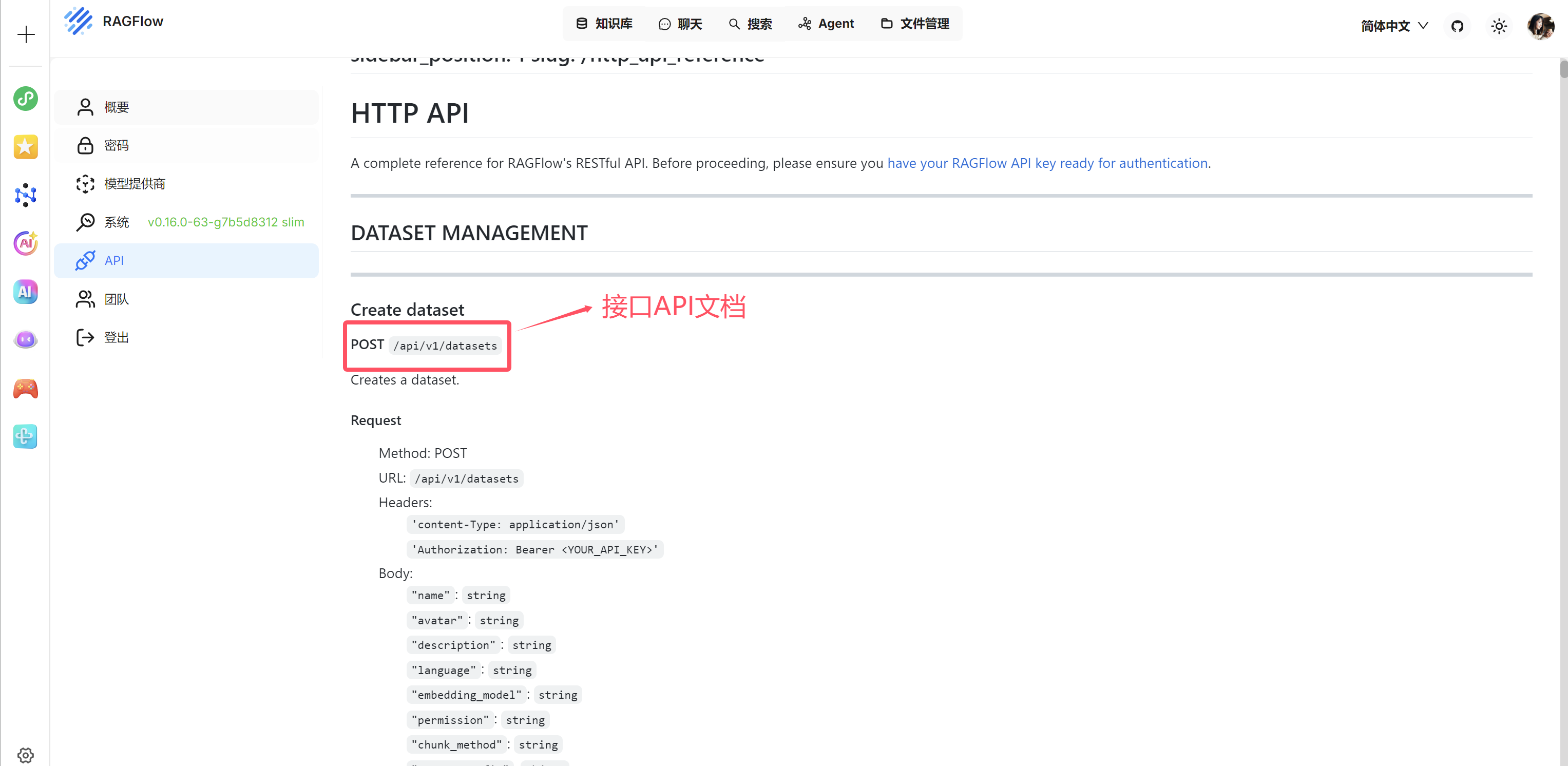
下面就是RAGFlow 对外提供的HTTP 请求API接口文档
六 dify配置外部知识库¶
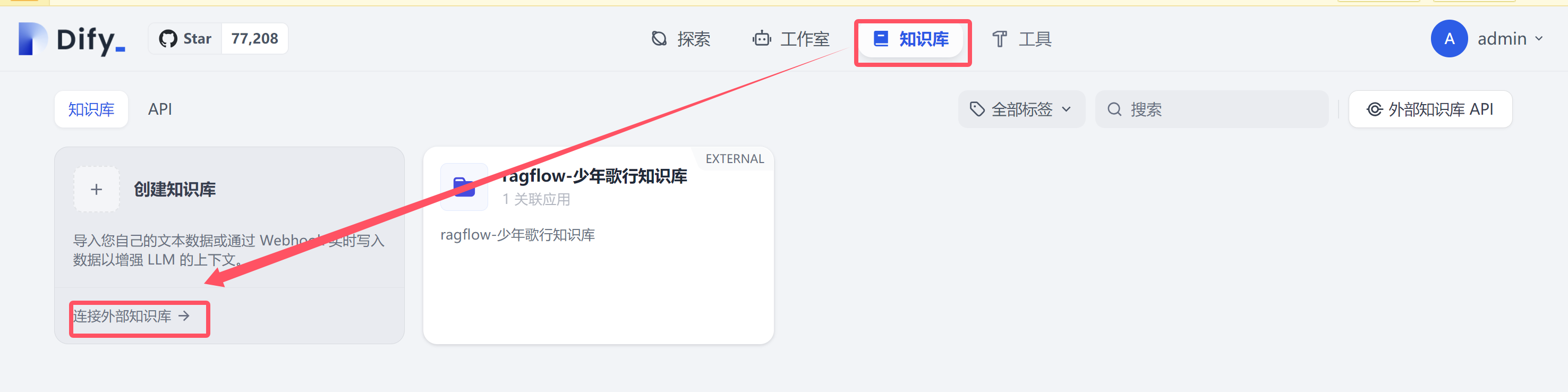
1 dify配置外部知识库¶
dify 工作流管理界面,点击上面知识库。点击链接外部知识库。
2 配置API¶
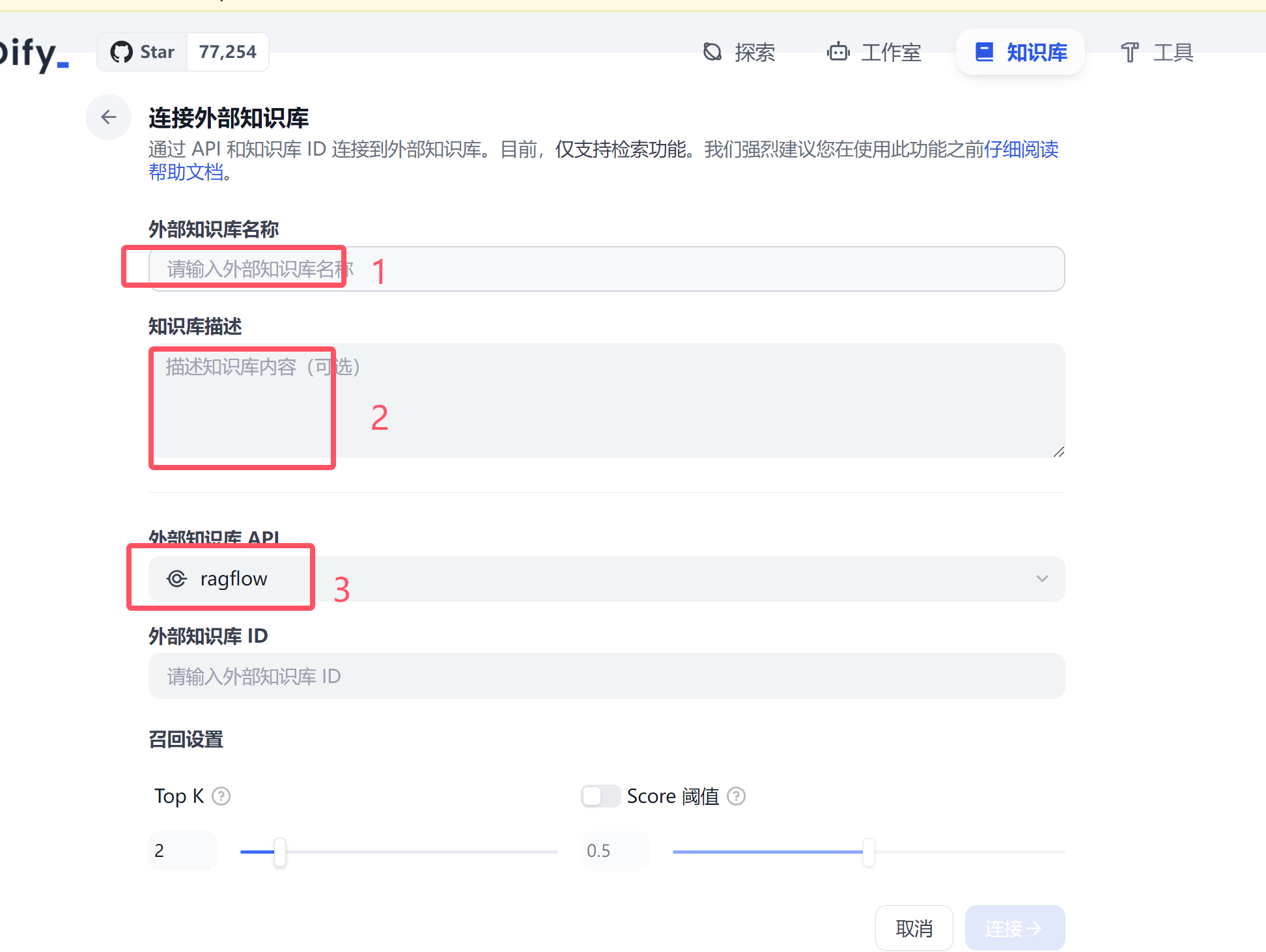
击右边的外部知识库API 先把外部知识库API 配置好。
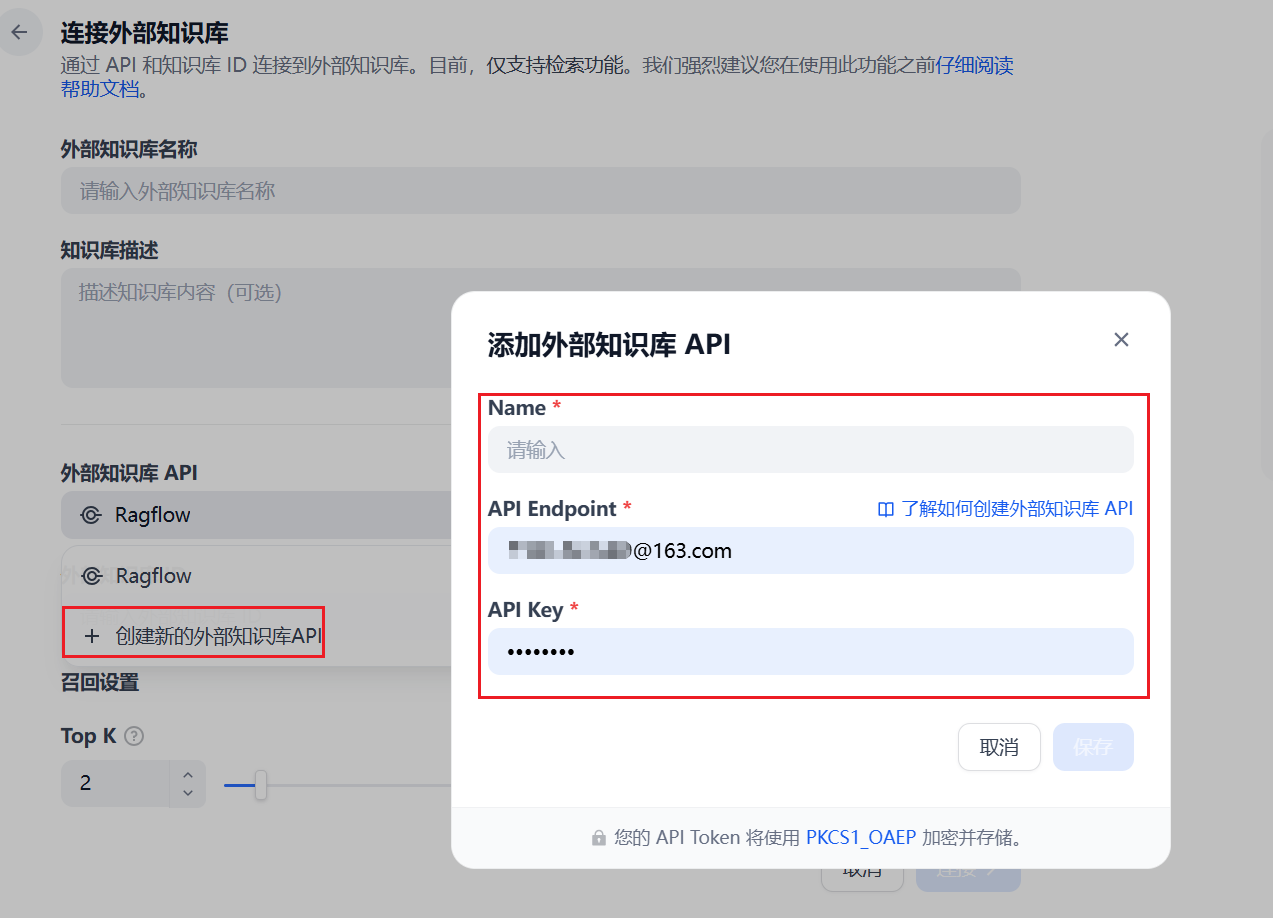
这里我需要添加3个值:
- name :随便写一个名字
-
API Endpoint 这个就是和RAGFlow 整合的地址。RAGFlow 对外提供的是192.168.xx.xx 这里填写http://192.168.XX.XXX:9380/api/v1/dify
-
api key 就是上面RAGFlow-开头的api KEY
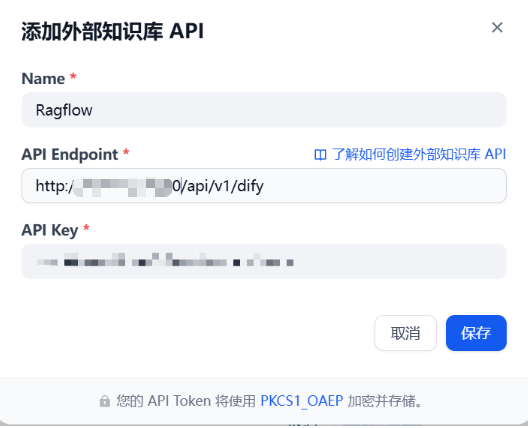
这里的 API Endpoint 的 IP 地址一定是要宿主机网卡上的 IP 地址,不要用 127.0.0.1 或 localhost
3 连接知识库¶
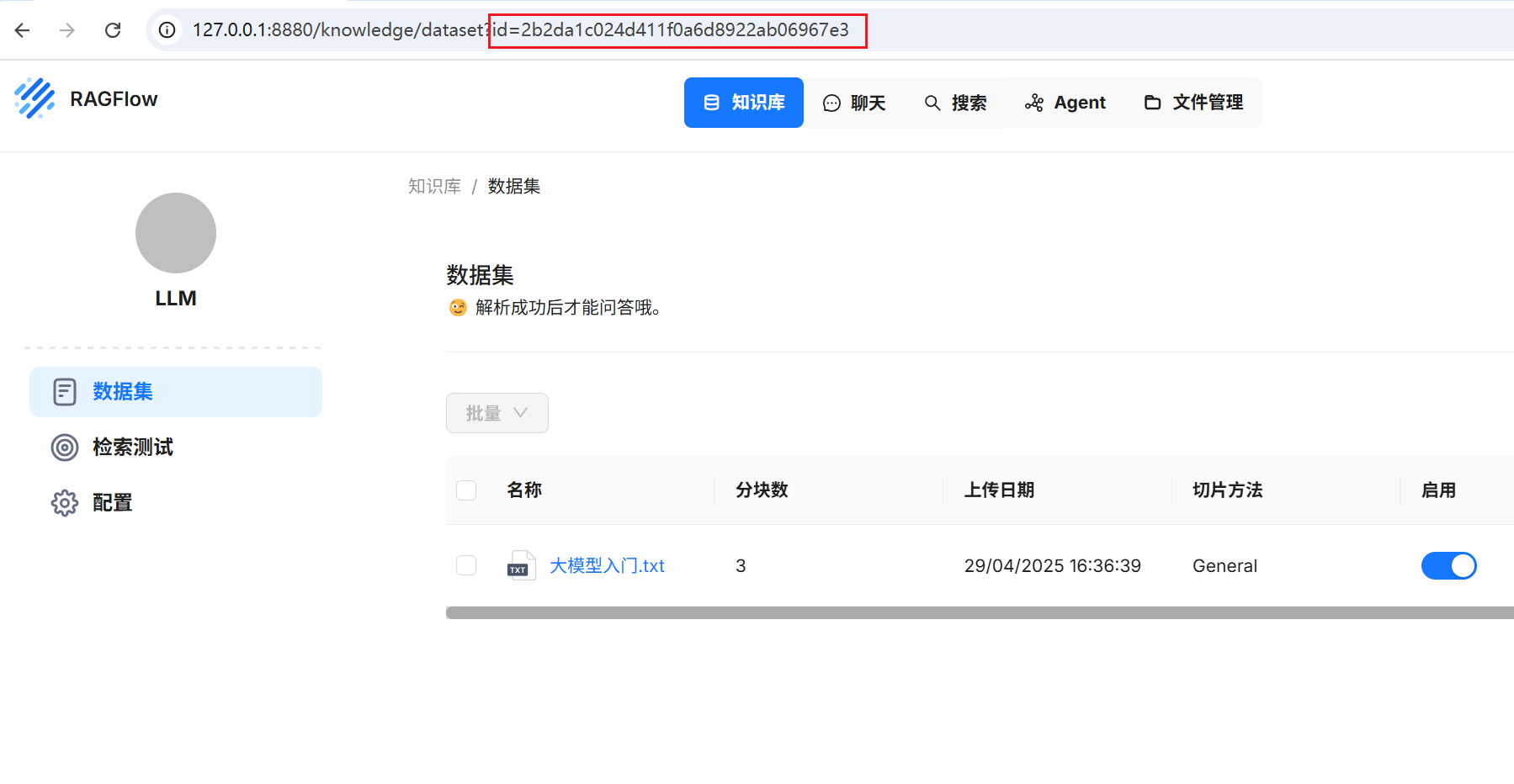
这个外部知识库 ID 如何获取呢?我们回到RAGFlow 知识库页面,从url中获取:
点击链接,完成RAGFlow和dify的链接
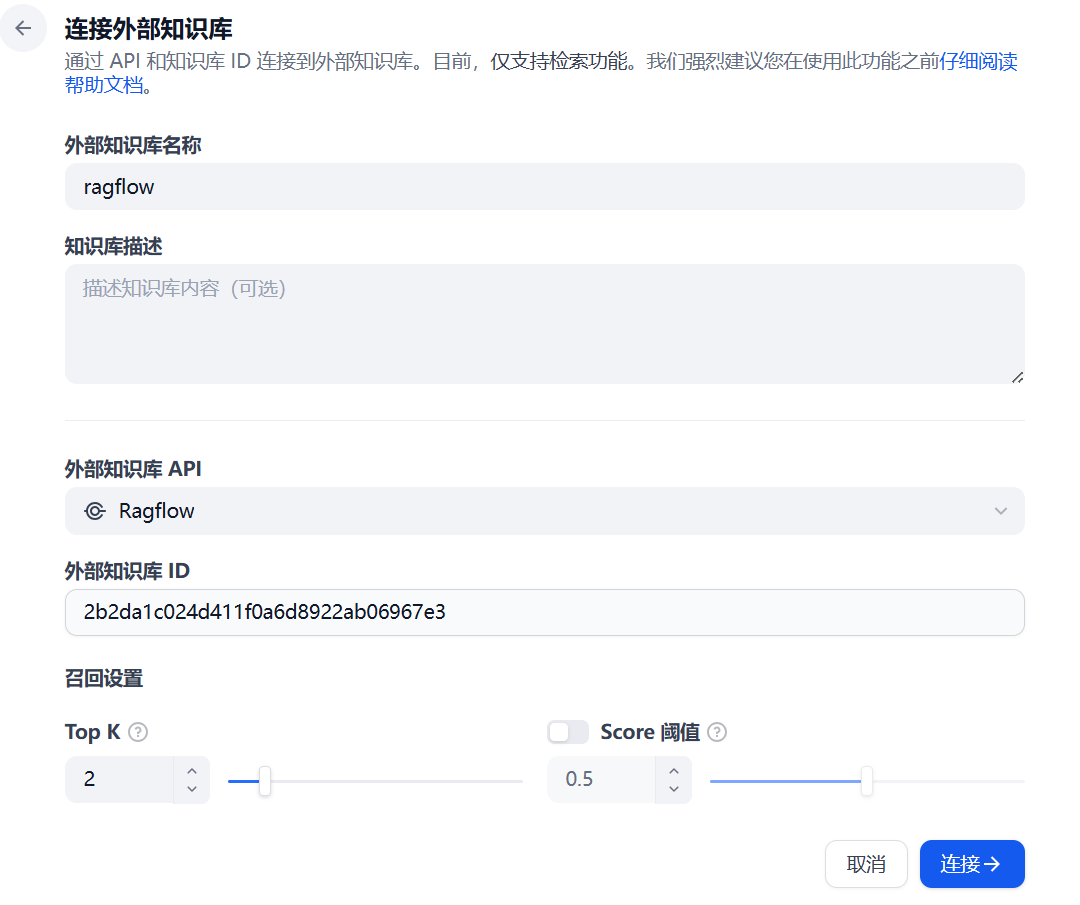
到这dify 和RAGFlow已经连接好了。
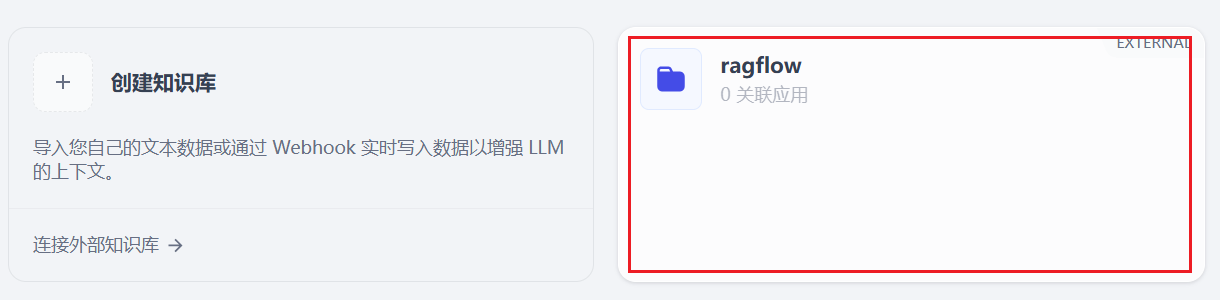
七、dify ai agent使用外部知识库¶
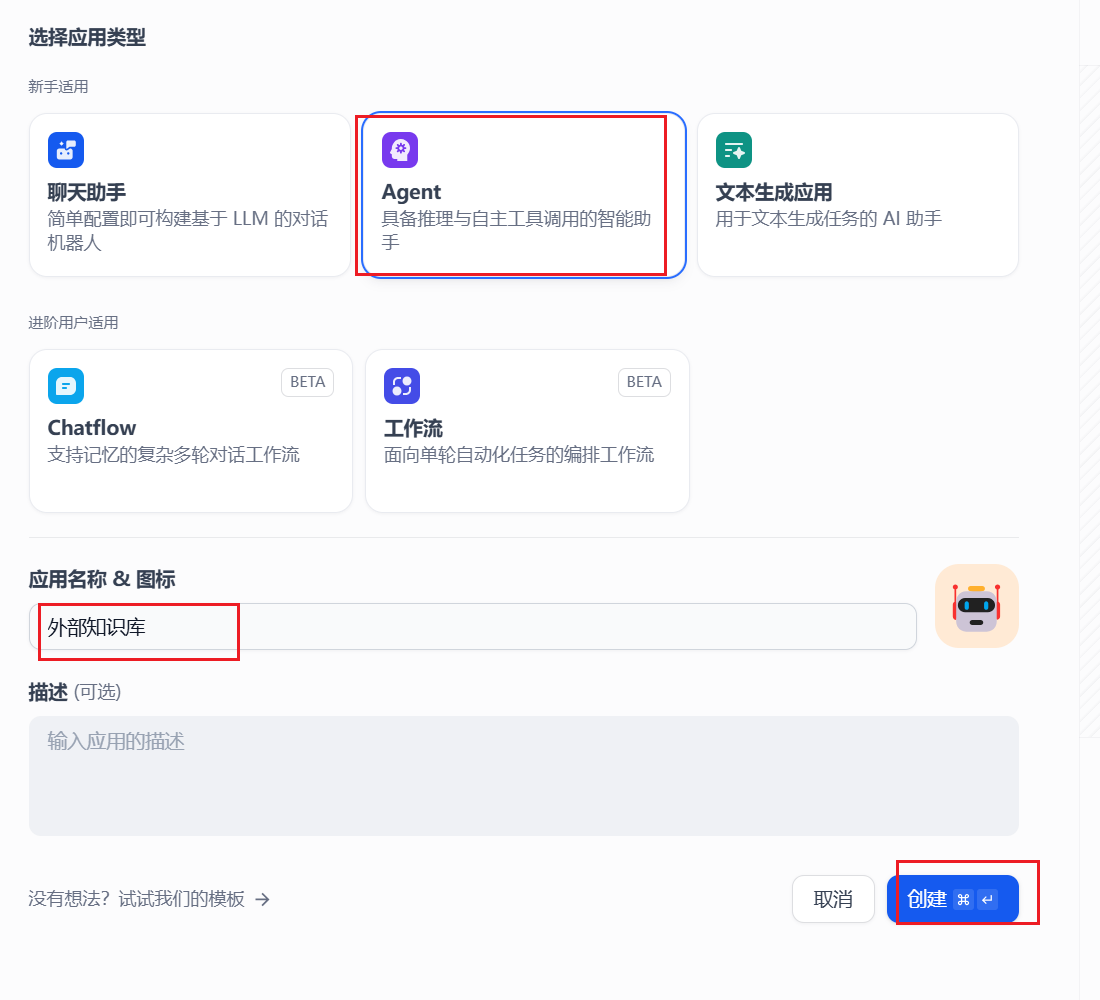
进入ai Agent 聊天界面,在上下文添加外部知识库。
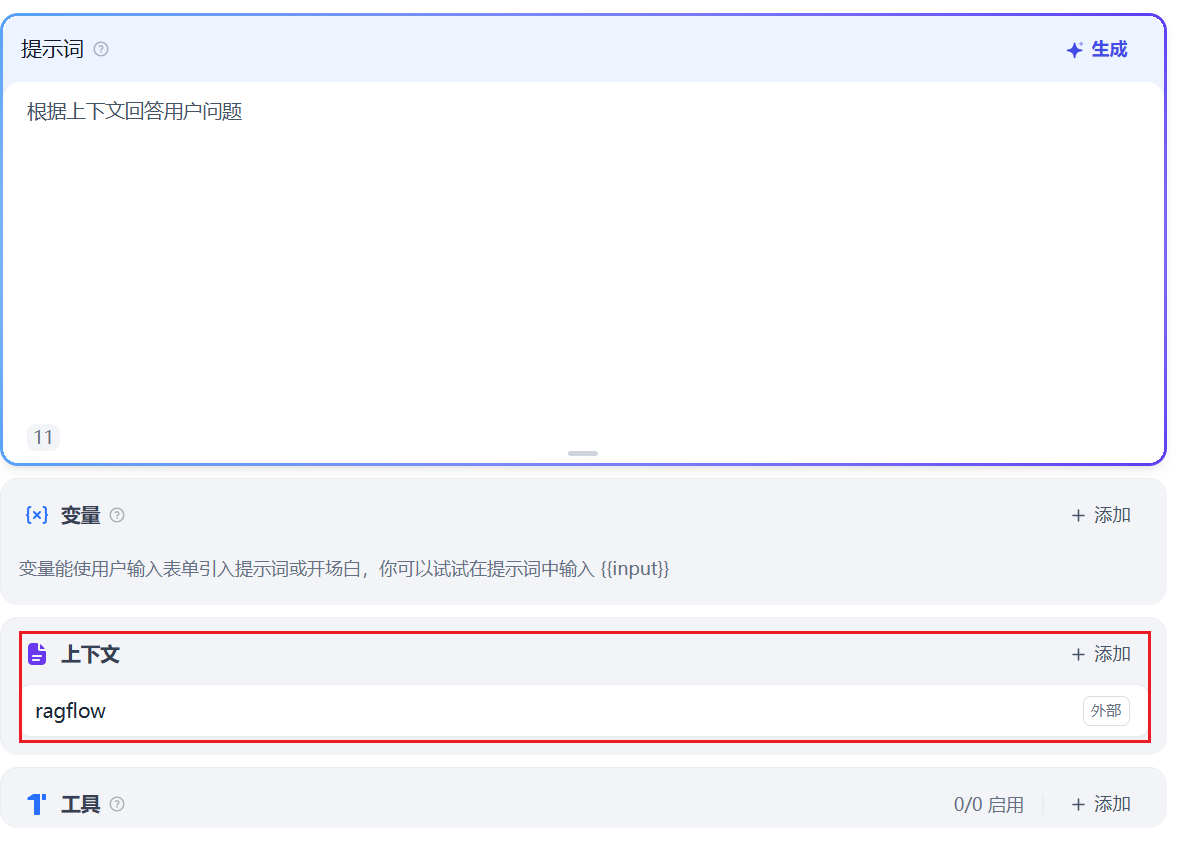
后面就可以进行知识库检索了,检索的是调用通过工具调用知识库。
到这在dify中调用RAGFlow中的知识库了。